






Customer closing account or showing reduced transactions/interactions over a set period.

Stops the business from becoming a "revolving door.“ and preserves revenue.

(a) No studies found linking causal analysis with client attrition in superannuation fund(s). (b) Most research focuses on churn prediction rather than causality analysis of customer churn.

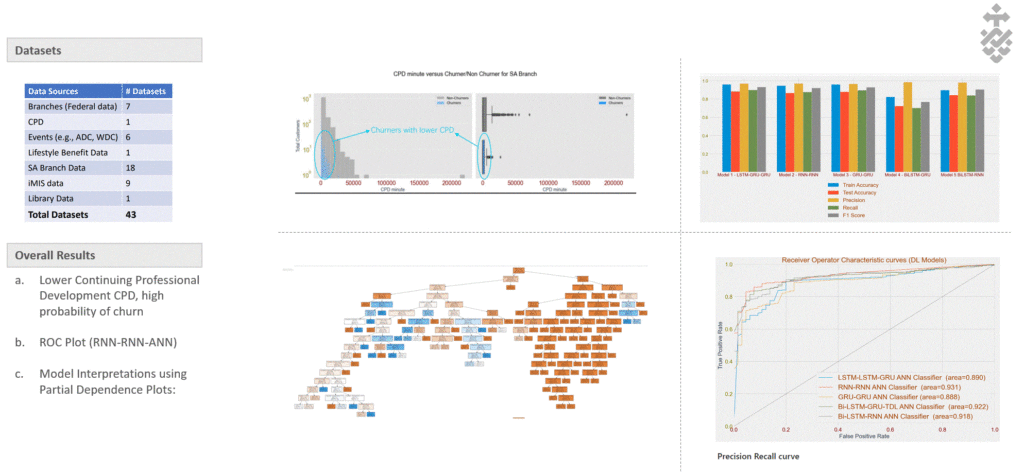
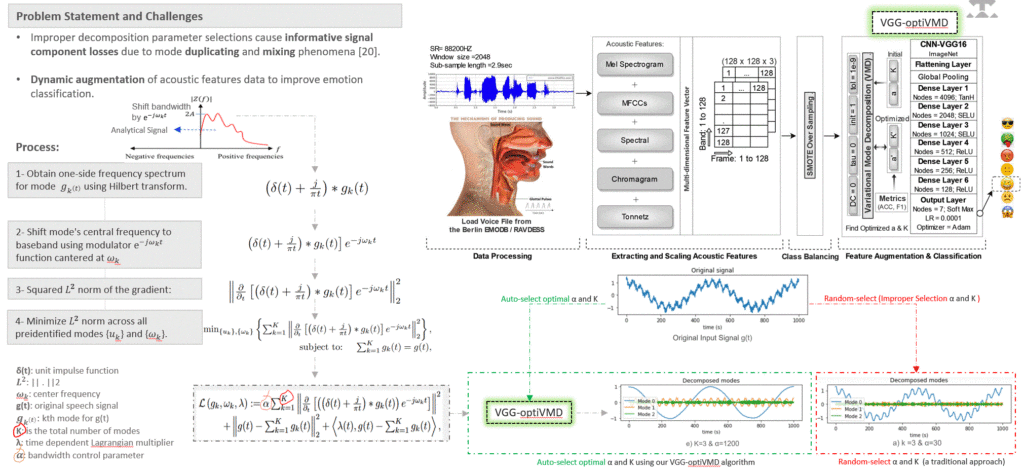
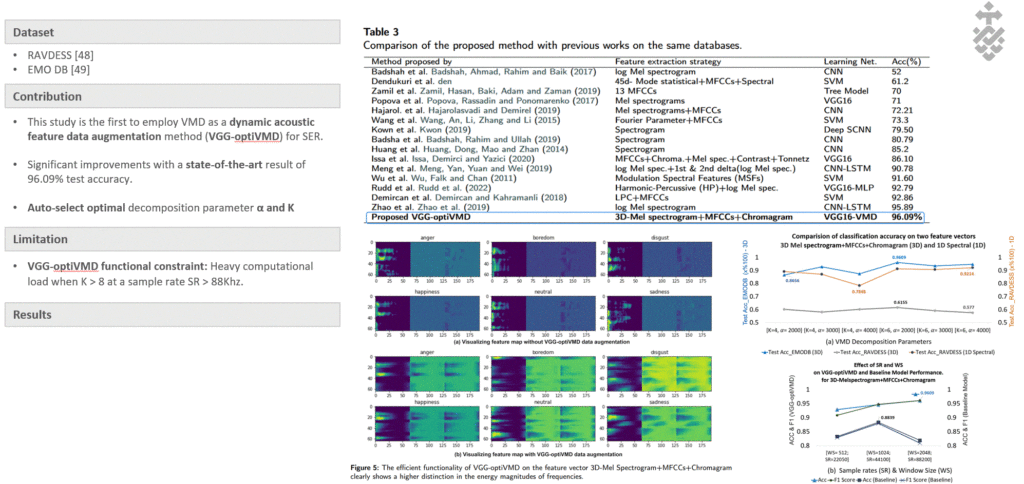
(a) Integrating RFE, SMOTE, and Ensemble ANN to address high-sparsity datasets. (b) Enhanced identification of causal effects and refined initial assumptions.

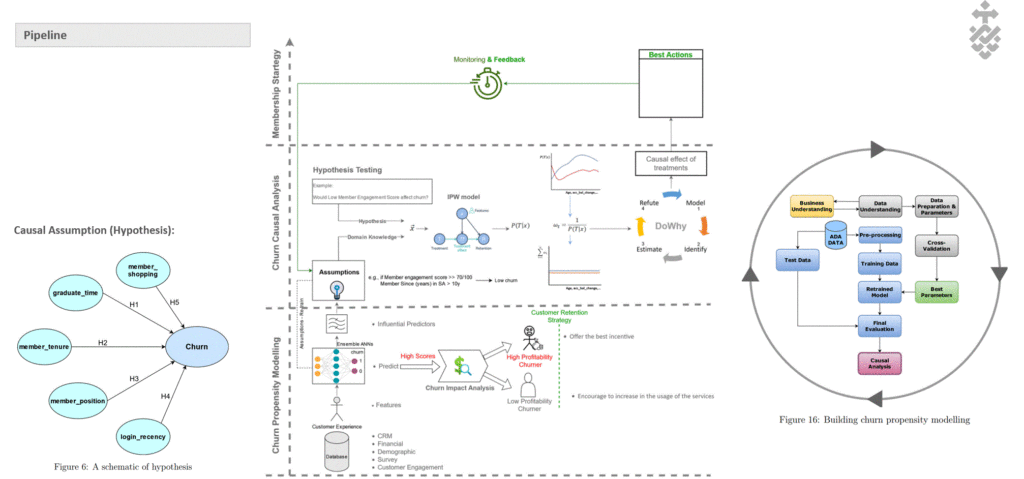
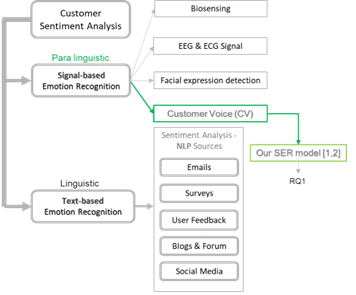
To address the complexity of the ANNs model, a causal inference model is proposed to identify churn effects of treatments and describe cause probabilities that lead to churn.

(a) Predicting potential churner within the next 6 months. (b) Causal Inference Model with IPW emphasising key robust Estimands.

The objective of this training estimate (task-1) is to predict the account balance of an bank customer with dataset in 2016 and 2017 using Pythonv 3.7. The dataset wa sourced from the CFD which is one of the largest company in supperannuation in Australia. This report is organized as follows:
1- Overview section describes the dataset used and the features in this dataset.
2- Data Preparation section covers data cleaning and data preparation steps.
3- Data Exploration section explores dataset features and their inter-relationships.
4- Methodology section describes how to estimate the customer’s account balance in the retirement age 67 and Program flowchart.
5- Summary and Conclusions section provides a summary of our work and presents our findings.
The CFD datasets provide two dataset features_201612.xlsx and features_201712.xlsx with a lot of features (culomns), but only age, current_balance, ID and SEIFA Index were useful in this project. The feature_description_jb.xlsx file contains the details of the variables (features or attributes). The dataset has 214296 observations. In this project, we use the dataset ” features_201612.xlsx” only to calcualte median growrth instances to growth_lastyear. You can find further information in methodology section.
Our goal is to see if we can predict an individual’s account balance in retired age 67 years within an acceptable increase or decrease in comparison with the amount of current account balance. we will predict account balance in age 67 based on the amount of median growth of the account balance in previous years and curent customer’s account balance.
Our target feature is account balance in age 67 years.
The variable descriptions below are from the feature_description_jb.xlsx file:
gender: Female, Male
age: customer age
acc_balance: account balance
acc_balance_201612: account balance in 2016
acc_balance_201712: current account balance in 2017
growth_lastyear: Median growth of customer account balance
seifa: SEIFA Index number between 1 and 10. Socio-Economic Indexes for Areas
postcode: Postcode
















By utilizing the median growth of previous account balances, we can project the account balance at retirement age. However, our approach has certain limitations, particularly for customers who are outliers or exhibit significant fluctuations in their account balances. While it proves effective for the majority of cases, a valuable next step would be to introduce interaction terms and consider incorporating additional features, such as the SEIFA index, to enhance the accuracy of our predictions. For instance, we could create a new variable derived from the SEIFA index number, which we could designate as the “SEIFA coefficient.”








