Posts
 Top Data Science News This Week
Top Data Science News This Week
- AI in Multiple GPUs: ZeRO & FSDP
- How Human Work Will Remain Valuable in an AI World
- 5 Ways to Implement Variable Discretization
- Stop Tuning Hyperparameters. Start Tuning Your Problem.
- Escaping the Prototype Mirage: Why Enterprise AI Stalls
- RAG with Hybrid Search: How Does Keyword Search Work?
- Graph Coloring You Can See
- Why You Should Stop Writing Loops in Pandas
- I Quit My $130,000 ML Engineer Job After Learning 4 Lessons
- Agentic RAG vs Classic RAG: From a Pipeline to a Control Loop
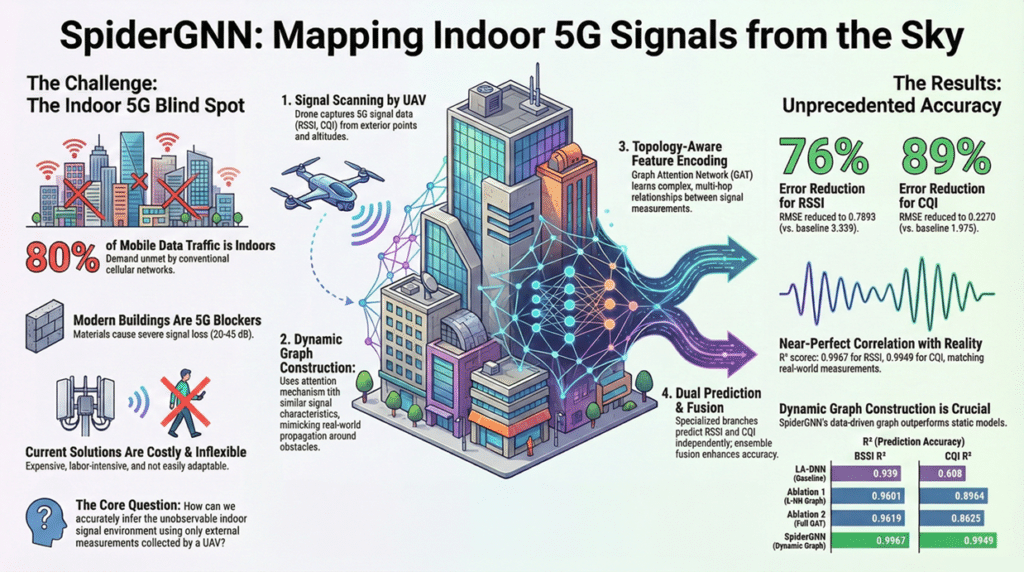
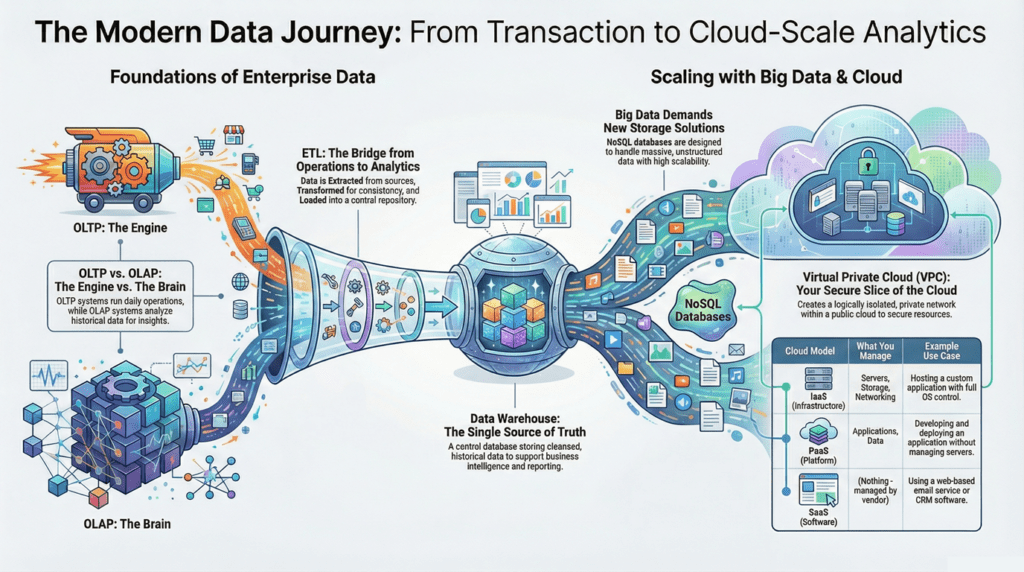

Understanding the Architecture of Data Warehousing
Data warehousing is critical for businesses looking to harness data for strategic decision-making. A data warehouse is a centralized repository that integrates current and historical data from multiple sources. It enables data analysis and supports business strategies by providing a unified platform for insights and decision-making. The process and structure of data warehousing can be complex, but let’s break it down with the help of a visual guide.
The Journey of Data: From Source to Insight
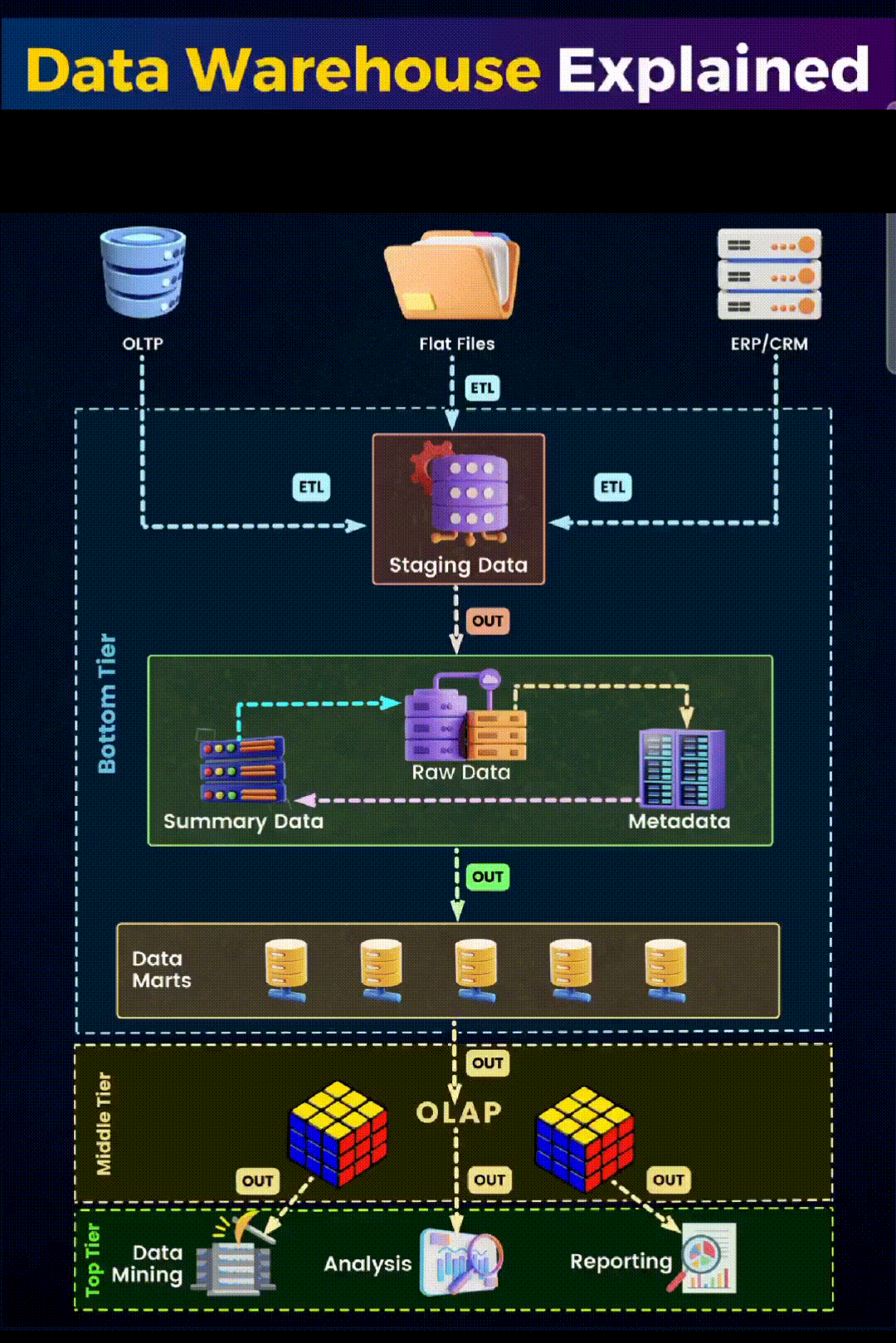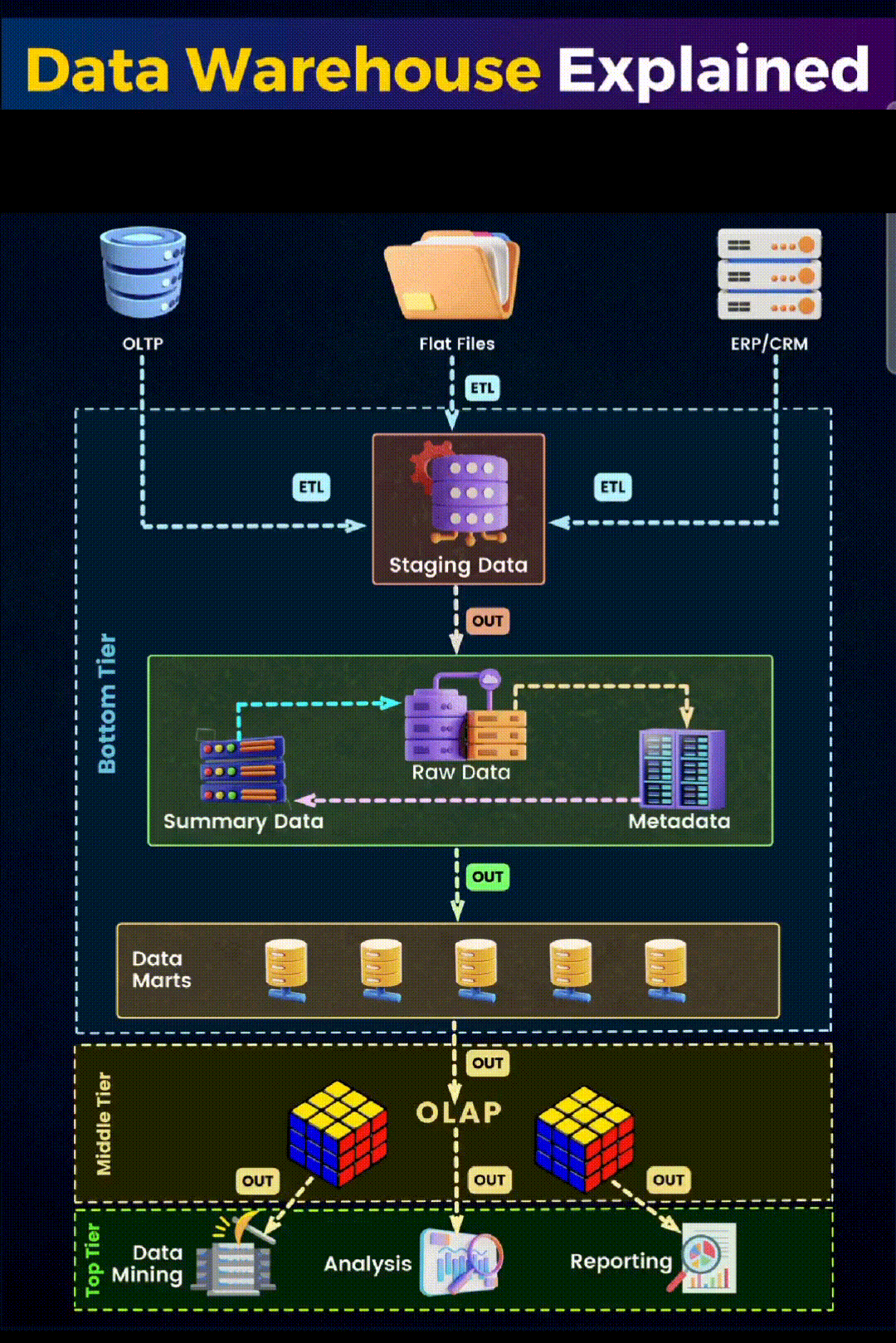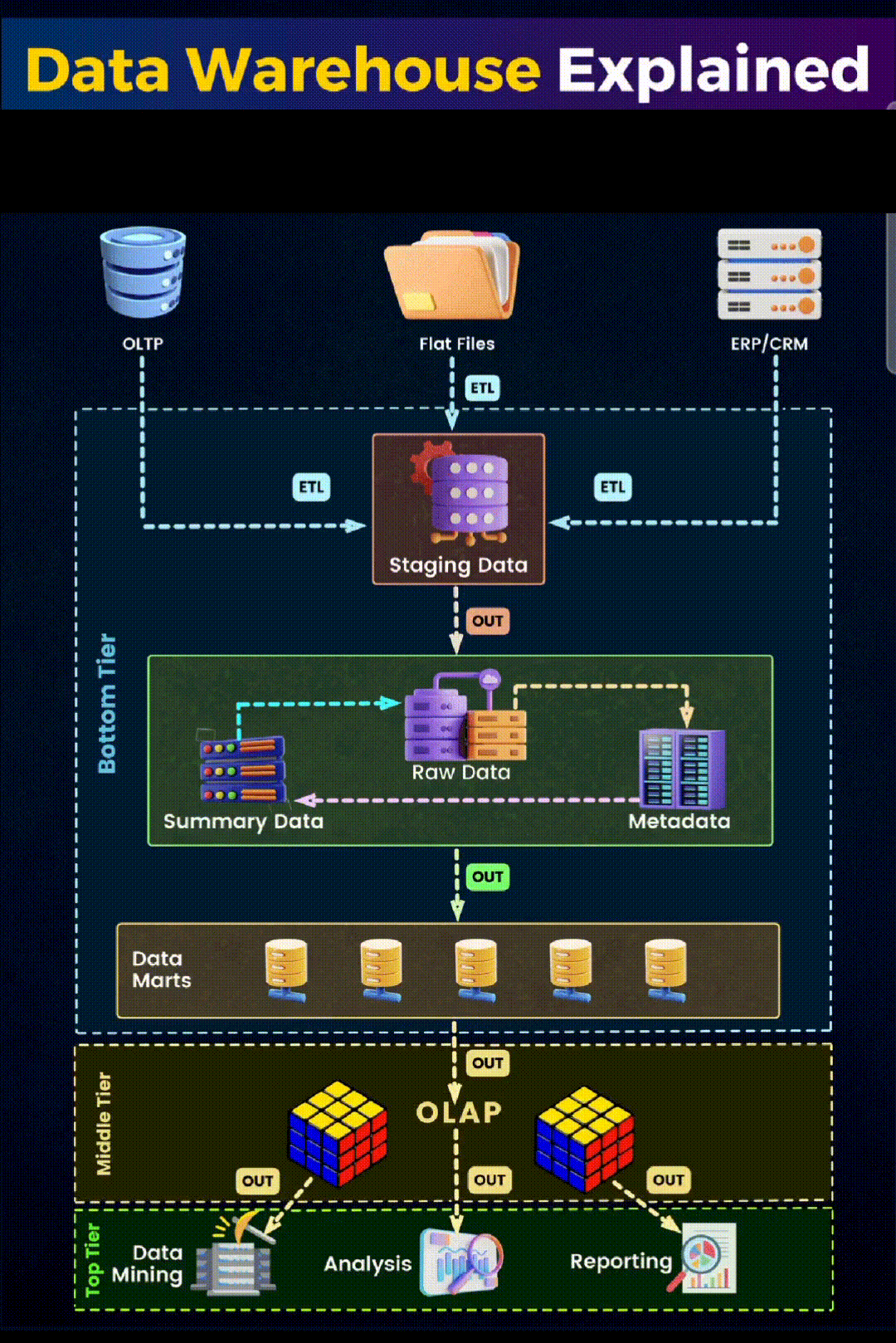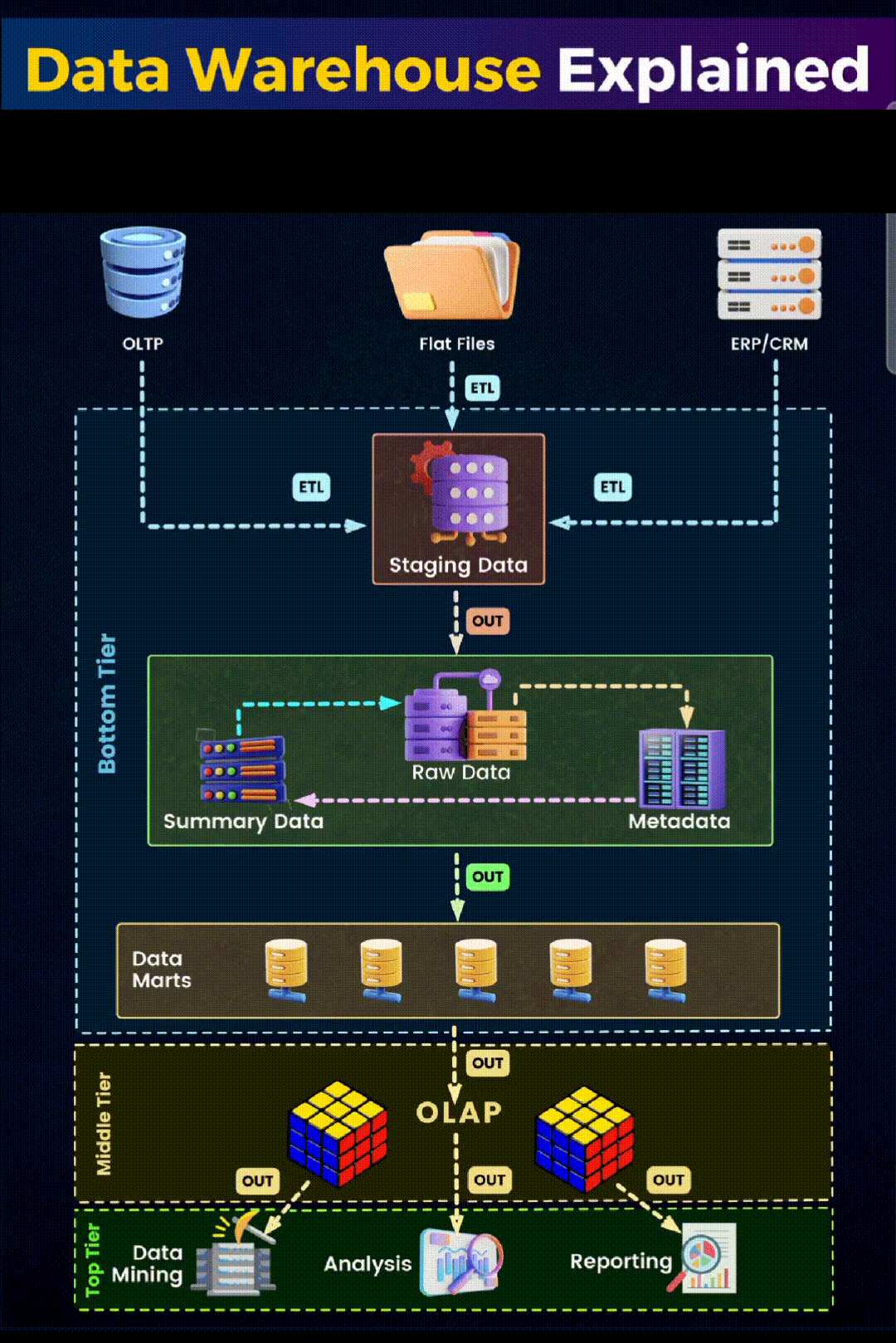
- Data Sources: It all starts with the data sources, which can be diverse. In our image, we see three primary types: Online Transaction Processing systems (OLTP), flat files, and enterprise resource planning (CRM/ERP) systems. These sources contain raw, operational data that reflect day-to-day business transactions and interactions.
- Extraction, Transformation, and Loading (ETL): In the ETL process, experts extract, transform, and load data. They cleanse, reformat, and integrate the data to ensure consistency. The staging area, as shown in the image, is the intermediary holding area where this process takes place.
- Data Storage: After ETL, data moves into the data warehouse storage. Here, we see it divided into two key components:
- Bottom Tier: This is where the actual storage of data occurs. It comprises the Raw Data, Summary Data, and Metadata. Raw data is the detailed data, summary data is the aggregated or calculated data, and metadata is the data about the data, providing context and definition.
- Data Marts: These are subsections of the data warehouse, often tailored to specific business lines or departments. They allow for quicker access to data relevant to specific queries or reports.
- Data Storage: After ETL, data moves into the data warehouse storage. Here, we see it divided into two key components:
- Data Access and Analysis: The top tier is where the action happens. This is the interface through which businesses interact with their data.
- Online Analytical Processing (OLAP): OLAP tools help in complex querying and offer multidimensional data analysis, allowing users to view data from different perspectives.
- Data Mining: This involves exploring large sets of data to find patterns and relationships that can lead to actionable insights.
- Analysis and Reporting: Finally, the analyzed data is presented through reports and visualizations, aiding in decision-making and strategy formulation.
- Data Access and Analysis: The top tier is where the action happens. This is the interface through which businesses interact with their data.
The structure of a data warehouse is designed to support business intelligence activities efficiently. From the initial data sources to the final analysis, each stage in the data warehouse architecture plays a crucial role in transforming raw data into valuable insights.

01.12.2023
Mixtral-8x7B-v0.1 Model Outperforms GPT-3.5!
Mistral.ai recently introduced the Mixtral-8x7B-v0.1 model, built using eight 7-billion-parameter Mistral models with a sparse mixture of experts (SMoE) approach. This model outperforms the 70-billion-parameter Llama and GPT-3.5 in most benchmarks and can now run locally with sufficient RAM and GPU. Initially shared via a torrent link, Mistral later provided detailed documentation following strong community interest. The model uses a Mixture of Experts (MoE) technique to combine eight expert models. The transformer architecture integrates two experts per token in each layer using the Mixture of Experts (MoE) technique. This replaces standard feed-forward layers, improving model efficiency and specialization by leveraging the expertise of selected models for specific tokens.

The MoE layer includes a routing network that selects which expert processes which tokens. This technique allows for an increase in parameters while controlling costs and speed, as the model only uses a portion of the total parameters for each token. As I mentioned, in Mixtral, two experts are selected at each moment, allowing decoding speed similar to a 12.9 billion model, even though it has four times more parameters (46.7 billion). Some mistakenly thought it had 56 billion parameters (8*7), but this is incorrect as only some feed-forward layers are repeated, not all parameters. If you’re a bit confused about MoE, don’t worry, I’ll explain it in detail in another post. That covers two of your requests.
We’re excited to inform you that both the base model and the Instruct model have been released. The context length is now 32,000. It performs equally or better than the 70-billion-parameter Llama2 and GPT-3.5 in most benchmarks. The results are attached below this post. It understands five languages: English, French, German, Spanish, and Italian (presumably trained on the togethercomputer/RedPajama-Data-V2 dataset, but that’s just my guess). It also performs well in coding tasks, reaching a score of 40.2 in HumanEval.
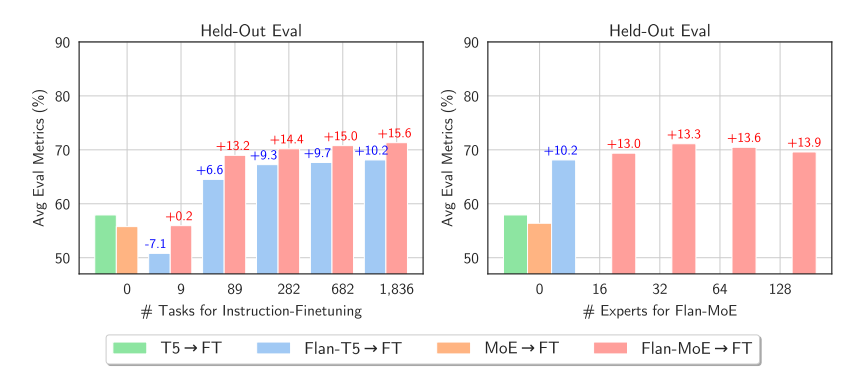
Lastly, it has been released under the Apache2.0 license for everyone’s benefit. The Instruct model has its own prompt format, which you can find in the links I’ve provided at the end. Like the Mistral 7B, we don’t know the dataset size, how it’s been preprocessed, or what data it includes for sft and DPO (for fine-tuning). The code for loading and inference is also in the links, but note that you’ll need at least 30 GB of RAM and a GPU like the A100.
Model release blog post link:
https://mistral.ai/news/mixtral-of-experts/
Link to the base Mixtral-8x7B-v0.1 model:
https://huggingface.co/mistralai/Mixtral-8x7B-v0.1
Link to the Mixtral-8x7B-Instruct-v0.1 model:
https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1
Hugging Face blog link:
https://huggingface.co/blog/mixtral
25.11.2023
A coronal mass ejection (CME) is a significant ejection of magnetic field and accompanying plasma mass from the Sun’s corona into the heliosphere 1. When a CME enters interplanetary space, scientists refer to it as an interplanetary coronal mass ejection (ICME). ICMEs are capable of reaching and colliding with Earth’s magnetosphere, where they can cause geomagnetic storms, aurorae, and in rare cases damage to electrical power grids 1. CMEs can travel at speeds ranging from slower than 250 kilometers per second (km/s) to as fast as near 3000 km/s 1. The fastest Earth-directed CMEs can reach our planet in as little as 15-18 hours, while slower CMEs can take several days to arrive 1. [1] https://en.wikipedia.org/wiki/Coronal_mass_ejection.
22/10/2023
Data Science
20.12.2020
Data Scientist:
- Statistical analysis
- Computer programs / Coding
- ML algorithms
Data Analyst:
- Large Data for business decision
- DBM SQL
- Complex business questions
- Communicate with data
- Between practical and theoretical aspects of data science
Data Engineer:
- Developing systems
- DB management
- IT Engineering background
Machine Learning Engineer:
- Computer engineer
- Software developer
- Coding & algorithm
 Corona Virus
Corona VirusJHU made a useful dashboard about Coronavirus. estimated that it would reach New Zealand, Iran, Indonesia, Turkey, Spain and Switzerland. However, nobody has been reported until now. Hopefully, it doesn’t reach to more countries. So, keep safe everyone! although, based on the probability theory and the law of saturation, the probability of getting this virus is very low for people of other countries except for Wuhan. David.
Update January 31: Modeling the Spreading Risk of 2019-nCoV
By Lauren Gardner, January 31, 2020
Collaborators
This work is being led by Lauren Gardner at Johns Hopkins University CSSE, in collaboration with Aleksa Zlojutro and David Rey at rCITI at UNSW Sydney, and Ensheng Dong at JHU CSSE. At JHU, we have previously developed an interactive dashboard mapping the outbreak in real-time, and a written a blog.
Model Implementation
This work builds on our previous analysis posted on January 26. We implemented a previously published model that integrates both outbreak dynamics and outbreak control into a decision-support tool for mitigating infectious disease pandemics at the onset of an outbreak through border control to evaluate the 2019-nCoV epidemic. A stochastic metapopulation epidemic simulation tool simulates global outbreak dynamics, incorporating airport entry screening to identify infected or at-risk individuals. A detailed description of the model is provided at the end of this section.
Our metapopulation model uses a global network of city-level populations connected by air travel routes, with outbreak dynamics modeled locally using a discrete-time SEIR framework. Air travel data from IATA informs the network’s weighted edges. Key parameters include a 5-day incubation and recovery period, with an effective reproductive number of 2, based on estimates from Imperial College London and NEJM. Initial cases are assumed to be in Wuhan, with no border controls. Results are averaged over 250 simulations.
Results
The results presented in this analysis are based on the 100 total cases of 2019-nCoV reported outside of mainland China on January 29. Specifically, we estimate the expected number of cases in mainland China at the end of January, as well as the global distribution of the infected travelers.
We believe the actual number of 2019-nCoV cases in mainland China are likely much higher than that reported to date. Specifically, we estimate there to be around 58,000 cumulative cases of 2019-nCoV in mainland China by the end of January (as of January 31, the reported cases is close to 12,000). This estimate is in line with our previous analysis on January 25, which estimated the proportion of reported to estimated cases to be close to 10%. It is likely that part of this discrepancy is due to reporting delays. However, the substantially larger number of estimated cases suggest a majority of the cases may be mild (or asymptomatic), do not require seeking medical care, and thus are not reported. Furthermore, based on this analysis, we believe the outbreak began in November, and there were already hundreds of human cases of 2019-nCoV in Wuhan in early December. The estimated verses confirmed cases during January are presented in Figure 1.
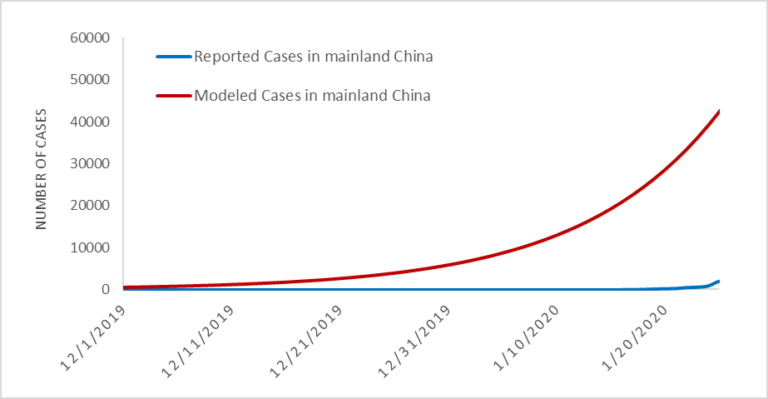
Figure 1. Estimated vs. Reported Cases of 2019-nCoV cases globally.
In addition to inferring the current outbreak size, the model provides the expected number of (the 100) imported cases arriving at each airport globally (based on final travel destinations of travelers). By aggregating this over all airports in a country/region we can estimate the total number of imported cases in each country/region. The country level importation risk is illustrated in the map in Figure 2, with the darker shades equating to higher importation risk, and the red outline indicating the set of countries reporting cases as of January 31.
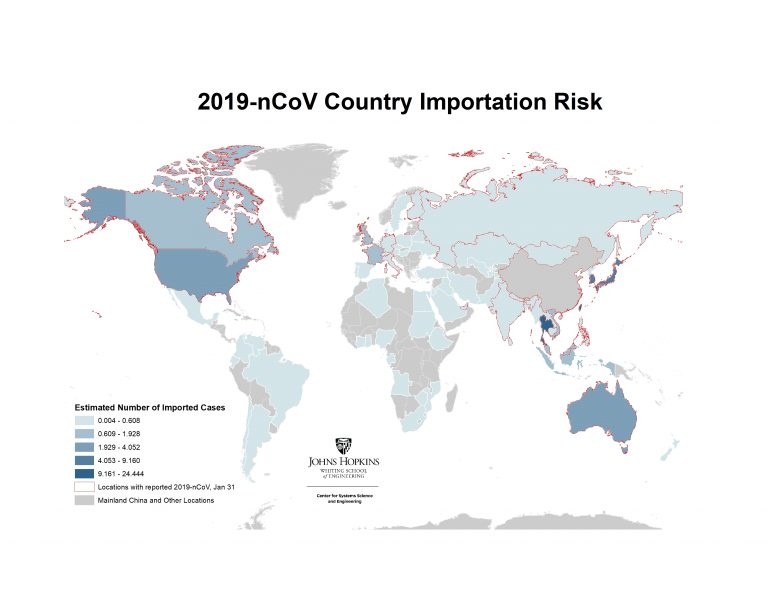
Figure 2. Heatmap of Countries/regions with highest risk of imported 2019-nCoV cases, January 31
Figure 3 below reveals how our estimated number of imported cases arriving in each country/region compared with the actual number of reported 2019-nCoV cases in each country. The simulation results align with the number of air travel reported cases outside of mainland China during the emerging stage of the epidemic. As of January 31, 24 countries excluding mainland China have reported at least one travel related case, with the list of affected countries consistent with our ranking. Some reported cases (shown as orange bars) were acquired locally in countries like the U.S., Germany, Japan, and Vietnam, contributing to the differences from our travel-related risk estimates.
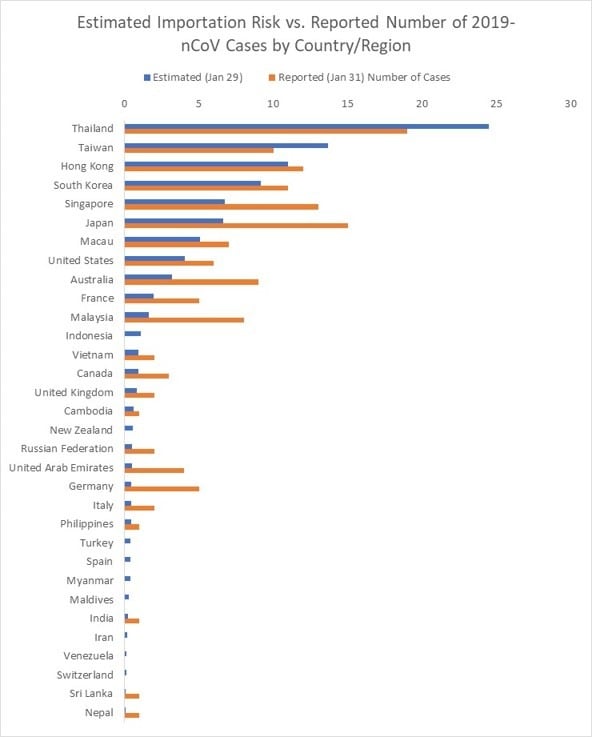
Figure 3. List of Countries/regions with estimated number of imported cases vs. reported number of 2019-nCoV cases (as of Jan 31) .
We further present the results at the airport level (based on their final travel destination), to identify the set of cities outside mainland China at highest risk of an outbreak. Figure 4 illustrates the set of cities within the U.S. at greatest risk of 2019-nCoV based on the expected number of arriving infected travelers at airports in the city, and the red outlines highlight the states that have already reported cases. The set of at-risk airports outside mainland China are illustrated in Figures 5, with the primary risk posed to southeast Asia. Only a subset of U.S. airports are listed in the top 100 globally. These results are consistent with our previous analysis on January 25. While many of these cities have already reported cases, they should be prepared for additional cases to be reported over the coming days, both in travelers whom departed Wuhan before the travel ban was implemented on January 23, and possibly through human to human transmission from infected travelers who arrived previously.
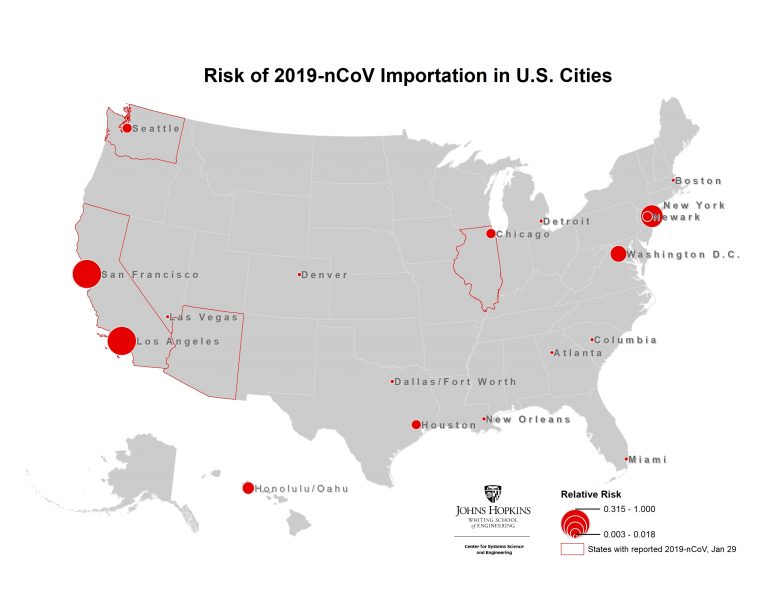
Figure 4. Map of highest risk U.S. cities based on likelihood of 2019-nCoV arriving travelers
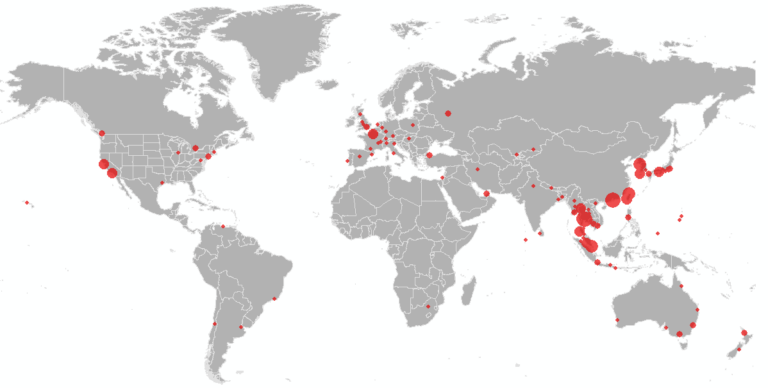
Figure 5. Map of the airports at highest risk of 2019-nCoV arriving travelers outside mainland China.
Limitations
The estimates are based on several assumptions and modeling limitations that must be thoughtfully evaluated.
- There is still uncertainty about the transmission of 2019-nCoV. The parameters for the reproductive number and incubation period chosen for this analysis align with the best estimates to date. There is less known about the duration of the recovery period, which may be longer than the five days specified in this analysis. More data will help us finer tune our estimates.
- This analysis does not account for infection transmission by asymptomatic individuals during the incubation period, despite recent confirmation of this phenomenon. It is therefore likely the number of reported cases outside of China will increase in the coming days, especially in those cities identified to be at highest risk in this analysis.
- The model only accounts for passenger air travel, and excludes mobility within and between cities via other modes of transport. Therefore, the spreading risk between regions connected via alternatives modes of travel is underestimated. This is most applicable to spread within China, which we are underestimating.
- The SEIR parameters used to model the outbreak within each city are deterministic. However, the spread of infected travelers moving between cities is modeled stochastically.
- The analysis does not account for the arrival passenger screening at airports or the complete air travel ban that authorities implemented in Wuhan on January 23. We are therefore likely overestimating the number of cases exported out of Wuhan during the last few days of our simulation. However, this is unlikely to impact the relative ranking of the destinations.
- This analysis assumes no local control mechanisms (such as prophylactics, vaccines, school closures, or quarantine efforts) are in place within cities. Therefore, the R0 is treated as constant over time and consistent across all locations. It is likely R0 is highly variable between locations, and lower than it was at the start of the outbreak, due to changes in individual’s behavior. Additionally, some higher R0 estimates based on the early stages of the outbreak are likely an overestimate at this point in time. For this same reason we may be overestimating the growth of the outbreak over the last week, and therefore overestimating total cases.
- We are using 2015 Travel data, because that is the most recent complete (airport-to-airport) data we had available in the lab.
References:
Zlojutro, A, Rey, D and L Gardner*. (2019) “Optimizing border control policies for global outbreak mitigation”. Scientific Reports 9:2216. DOI https://doi.org/10.1038/s41598-019-38665-w (Open Source link) https://rdcu.be/bniOs
Worlds of innovation
You have to have a big vision and take very small steps to get there. You have to be humble as you execute but visionary and gigantic in terms of your aspiration.
In the Internet industry, it’s not about grand innovation, it’s about a lot of little innovations: every day, every week, every month, making something a little bit better.
Time is money
02/04/2018 BUT THAT DOESN’T MEAN YOU HAVE TO WORK NON-STOP
A key principle of labor is that time equals money: the less time you waste, the more tasks you accomplish, and the greater your earning potential becomes. Don’t dilly-dally! If there’s time for learning, there’s time for cleaning, as one popular barista equivalent goes. Benjamin Franklin, the great aphorist, often assigned the phrase in his 1748 essay “Advice to a Young Tradesman.” He wrote, “Remember that time is money,” and then went on to remind his youthful reader of the opportunity cost of laziness.. When you’re not working, he says, you’re just throwing potential earnings away. But the money-time equivalency had been a meme for quite a while before Franklin got his literary-kleptomaniacal hands on it. The connection between the two has never quite remained the same over the past two millennia, and in our age of digital labor, we’re redefining the relationship between time and money yet again.
LIFESTYLE COMPANIES “BUILD A SUSTAINABLE REVENUE STREAM,” “STAY AS SMALL AS POSSIBLE,” AND “WORK HARD, BUT AIM TO MINIMIZE HOURS WORKED.”
It’s feeling like past time for me to wrap up this blog, however. I’m still operating under the premise that time is very much money.

12/05/2017
2000s: Talking is cheap show me your code
2026: Code is cheap show me your prompt
2027: Prompt is cheap show me your GPU credit
#NVIDIA
#ComputeIsCurrency
#H100
#CloudComputing
#AIInfrastructure
Deconstructing Emotion via @YouTube
Antigravity: Build any app in a minute via @YouTube
TEQSA RPL Automation App via @YouTube
AI Meets the Mind via @YouTube
AI Meets the Mind https://youtu.be/S2KUOSOObiY?si=ZxY7xSZFmx_akm9J via @YouTube
Cybersecurity in Big Data https://youtu.be/ar8PAEI5oZM?si=8nUfjevN-b04vAmv via @YouTube
#AgenticAI,
#CyberSecurity,
#CloudSecurity,
#CloudProtection,
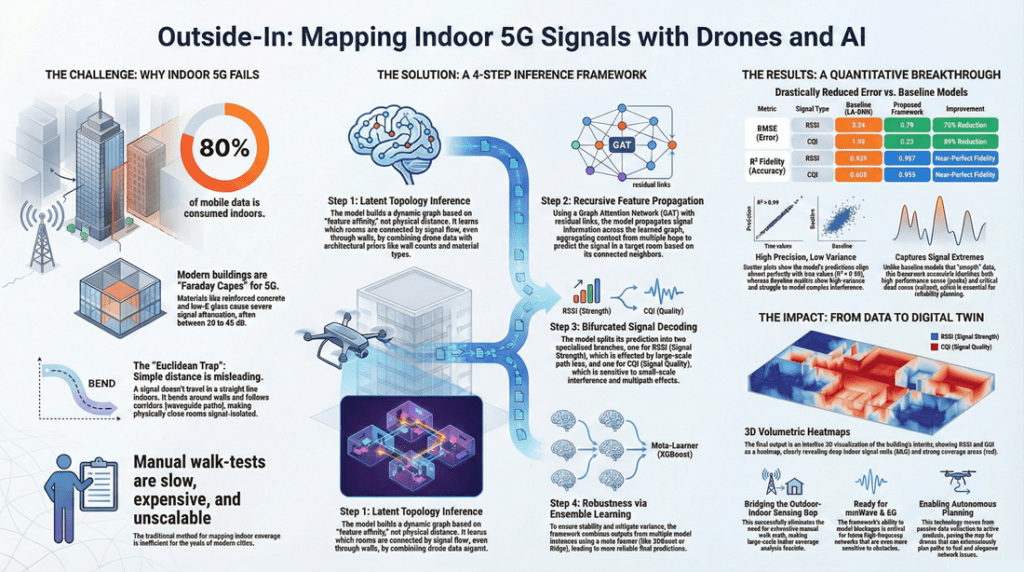
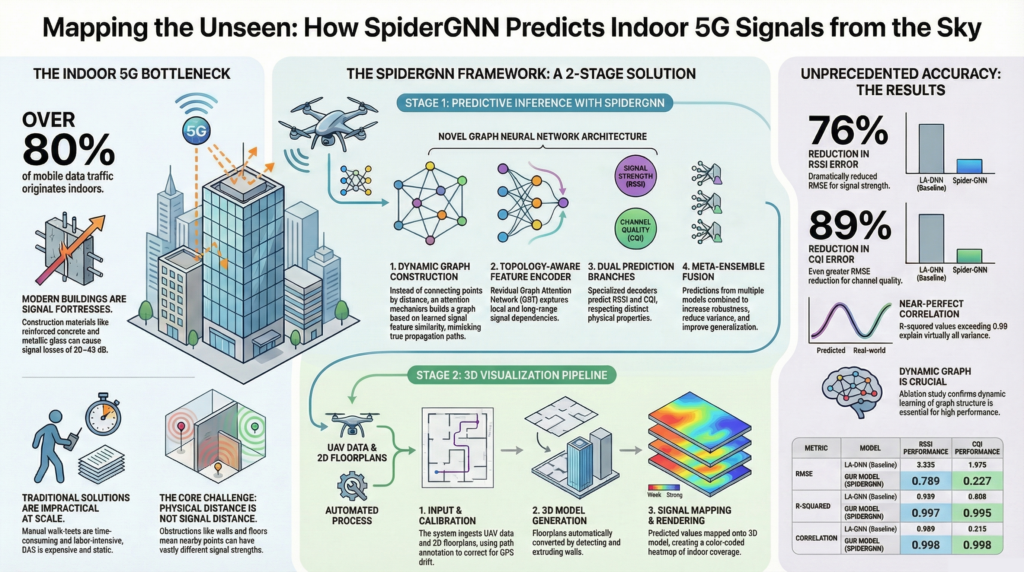
SpiderGNN: Seeing 5G Signal Through Walls via @YouTube
Taming the Digital Deluge https://youtu.be/usfab542IQo?si=kBl6aaBYrrHRbsI1 via @YouTube